Tutorial¶
CADS (Catalyst Acquisition by Data Science) is a data platform designed for catalytic data analysis for catalyst developers and researchers. This tutorial aims to help users in becoming more familiar with the functions provided by CADS.
We welcome any and all feedback for bugs, site usage, and additional functions for data analysis for improving this platform.
The Function of CADS¶
CADS is a catalyst analysis environment that implements a user-friendly graphic user interface(GUI). CADS provides three basic functions for users: “Data Management”, “Analysis”, and “Prediction”.
Data Management: CADS provides the ability to upload and record individual data as well as data analysis procedures with the option for multi-user sessions, allowing users to share data and analysis reports with collaborators of their choosing.
Analysis: Data visualization tools (scatter plotting, histograms, etc.) and machine learning functions are availabe for catalyst data analysis and machine learning model selection.
Prediction: Data prediction capabilities are available with the “Analysis” function, allowing users to apply learning models for predicting new output (e.g. predicting new catalysts).
A Brief Tutorial for Beginners¶
CADS is a free platform that does not require additional software installation. It can be easily accessed by visiting “https://cads.eng.hokudai.ac.jp” through your internet browser. Site operation has been tested through Google Chrome,Mozilla Firefox, and Microsft Edge. Site operation has also been tested on Windows, Mac, and Linux operating systems. Should bugs or other issues arise using the platform, please do not hesitate to contact us.
Below, we have outlined a brief workflow for CADS.
Site Login¶
When logging into your account, the login window should appear on the website as shown below. Please login using your individual ID and password.

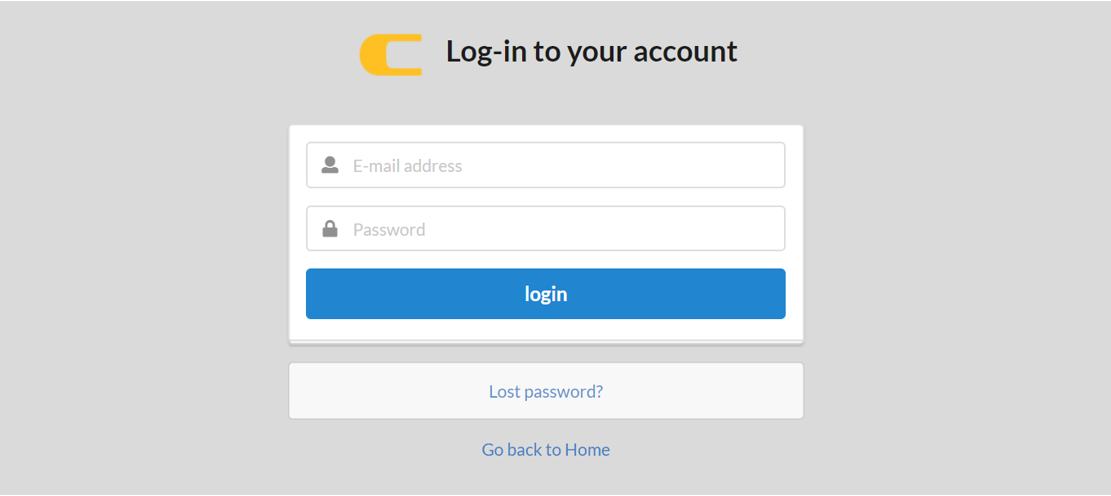
The following window will appear once user authorization is successful. You can check the applied e-mail address for log-in and the “log out” buttone in the upper right corner of the webpage.

Uploading Catalyst Data¶
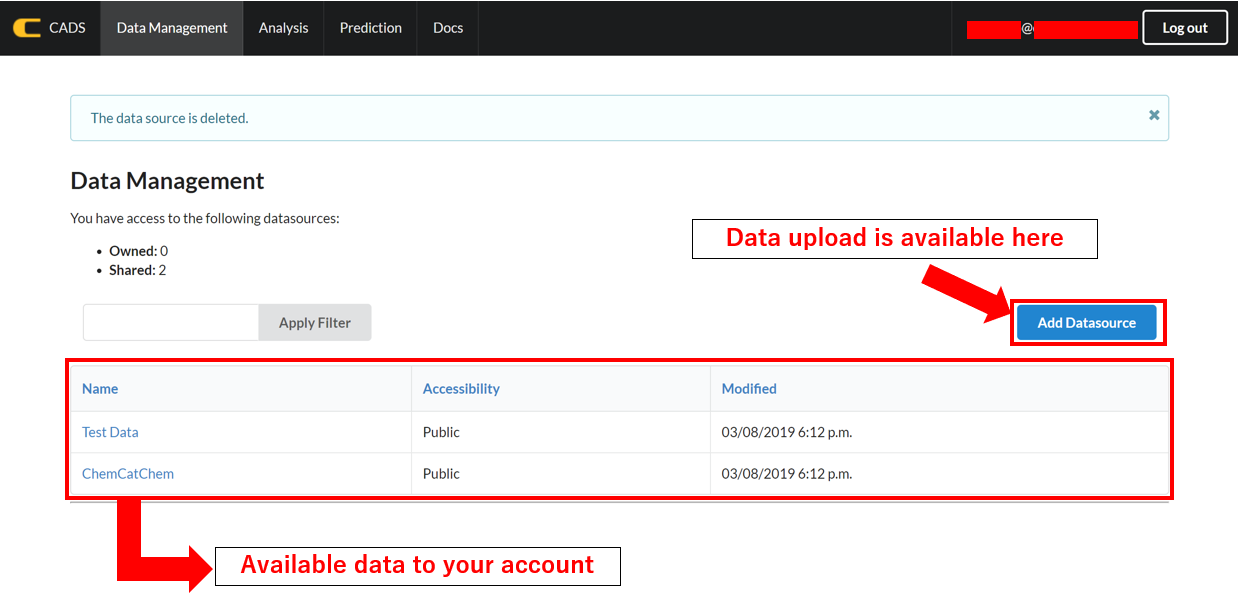
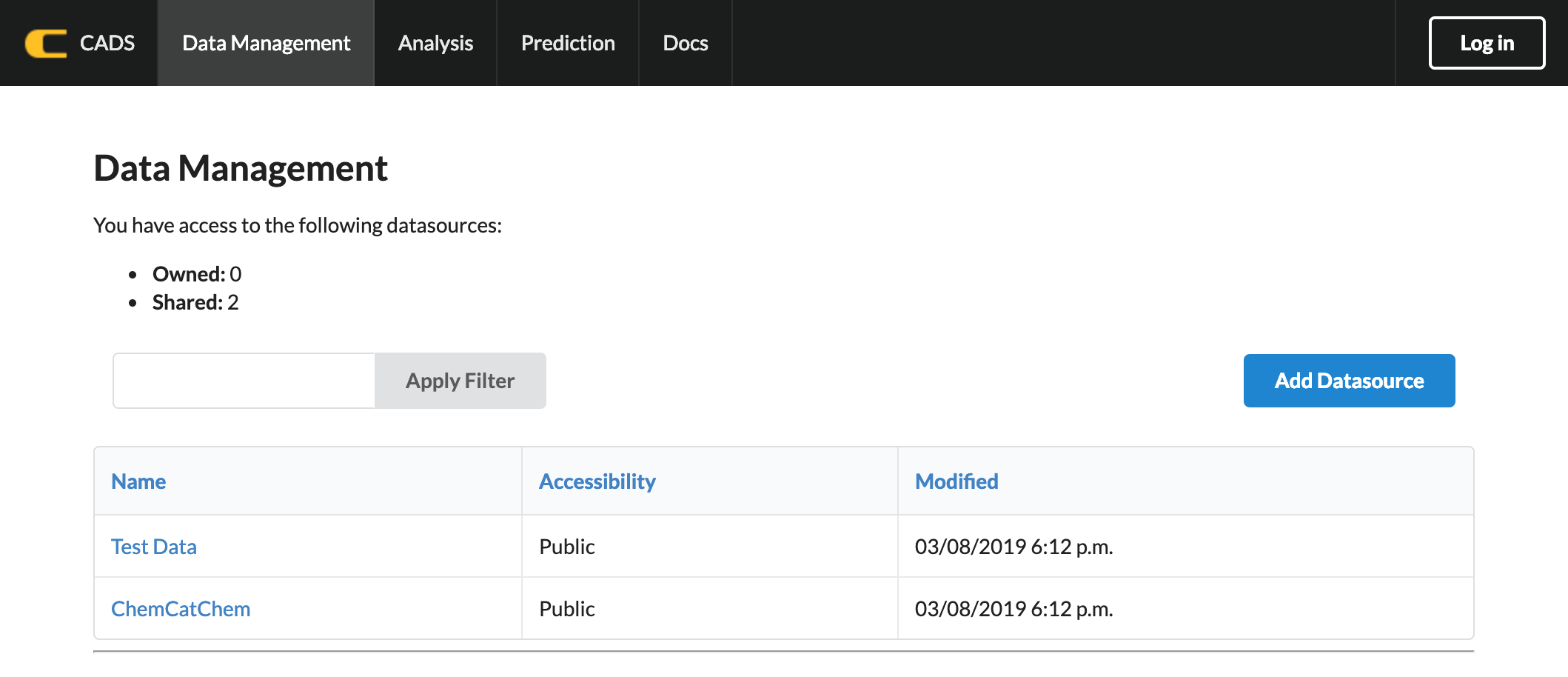
CADS provides a data analysis environment that can be used with data uploaded into your account. Data uploading is available in the submenu “Data Management” that appears at the top menu bar. In the “Data Management” window, data that is available to your account will appear, including both “public” data and “shared” data. To upload data to your account, click “Add Datasource” on the upper right corner of the menu bar.
The following window will appear after clicking. Data can be uploaded by following the instructions on the window.
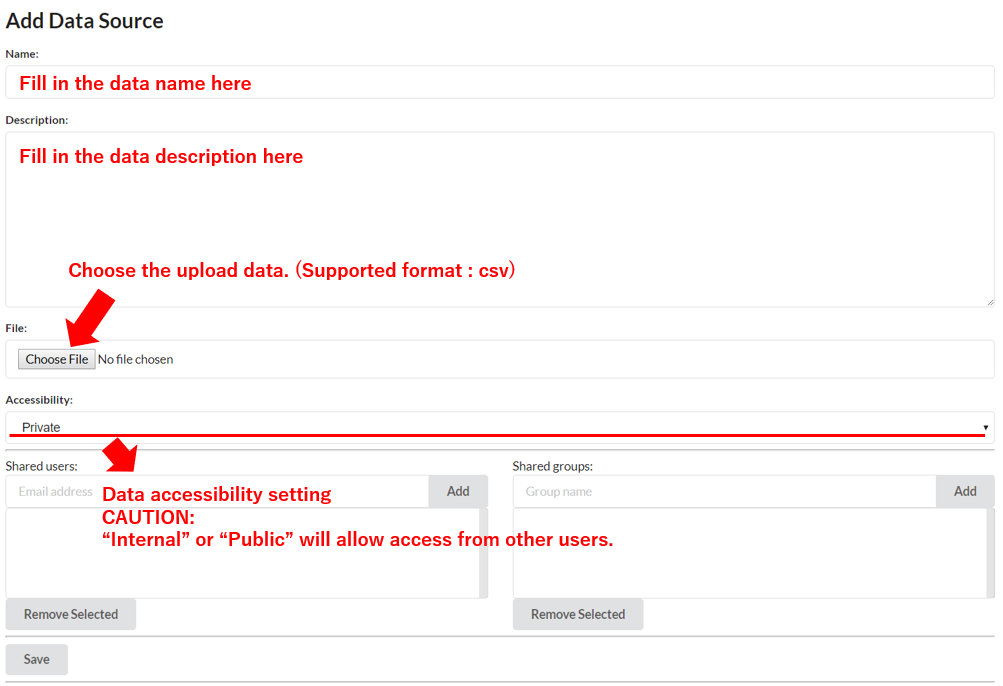
CAUTION:
"Accessibility" is the setting window for the user accessibility of uploaded data.
PLEASE SET IT AS "Private" IF YOU ARE A BEGINNER OF THIS PLATFORM.
The setting "Public" allows other site users to access your uploaded data.
The data becomes available once uploading is complete and will be listed under the “Data Management” list for analysis.
Data Management Functions¶
Data properties can be changed after uploading data by clicking the listed data you would like to change. After clicking the data, a data table will appear with the “Setting” menu on the upper left corner of the window.
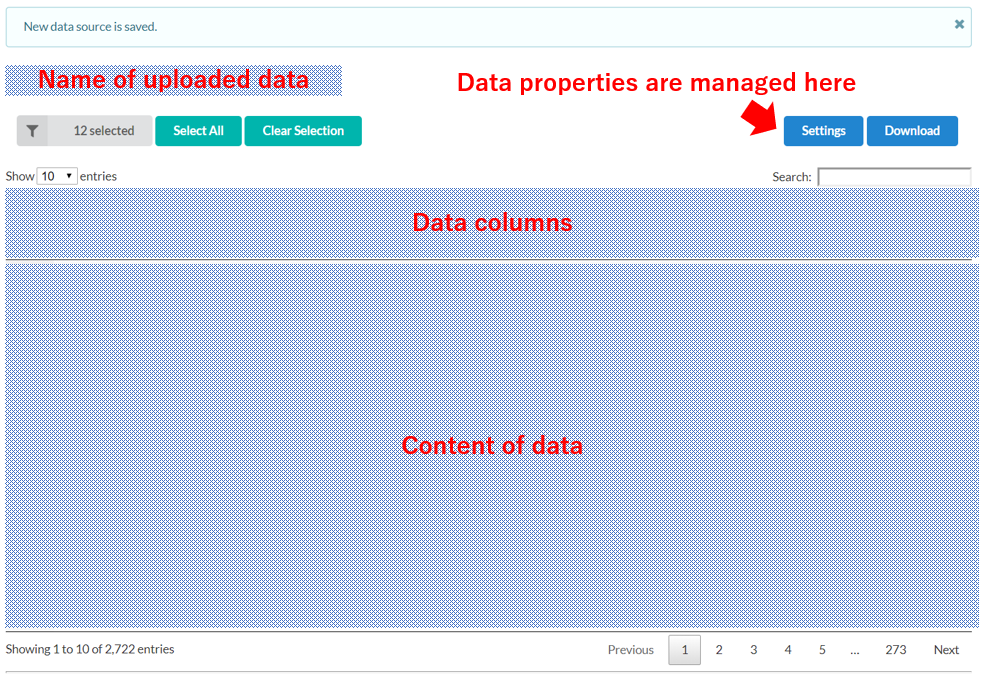
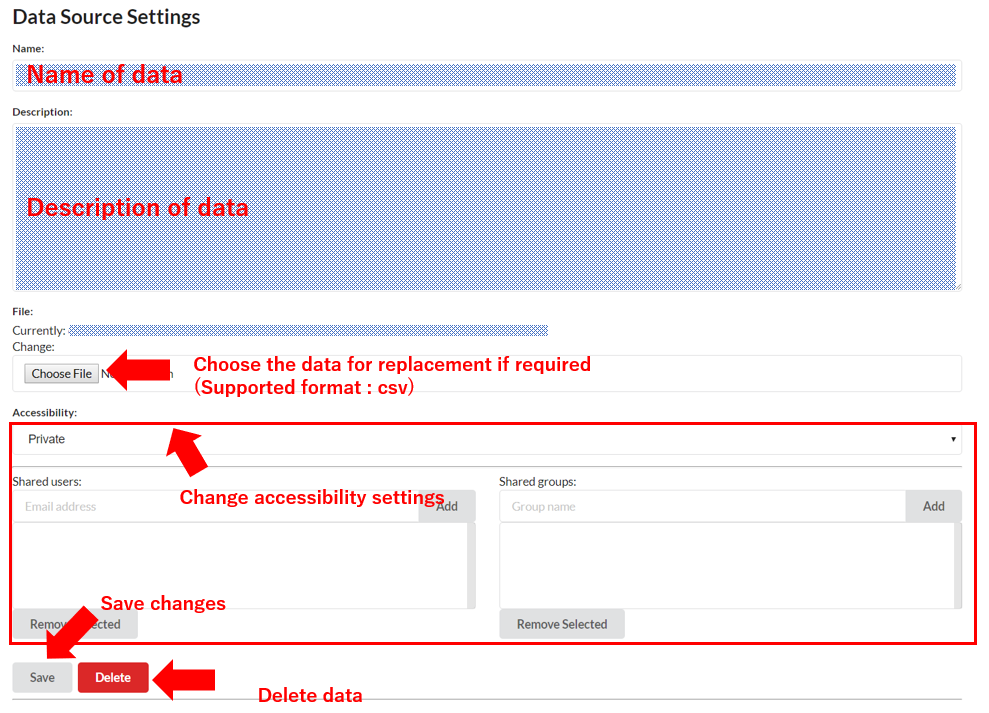
In the Setting menu, the following data properties can be modified: Data Name, Data Description, Data Replacement, and Data Accessibility. The ability to delete data is also available within the same menu.
Saved Data¶
A list of uploaded (or accessible) data can be confirmed by clicking “Data management” in the menu bar. The listed data is browsable as a data table and can be modified with the following actions: deleting unnecessary columns, filtering by keywords.
As a tutorial, sample data “ChemCatChem”, a dataset consisting of experimental catalyst data of Oxidation methane coupling(OCM) reaction, is available for all users.
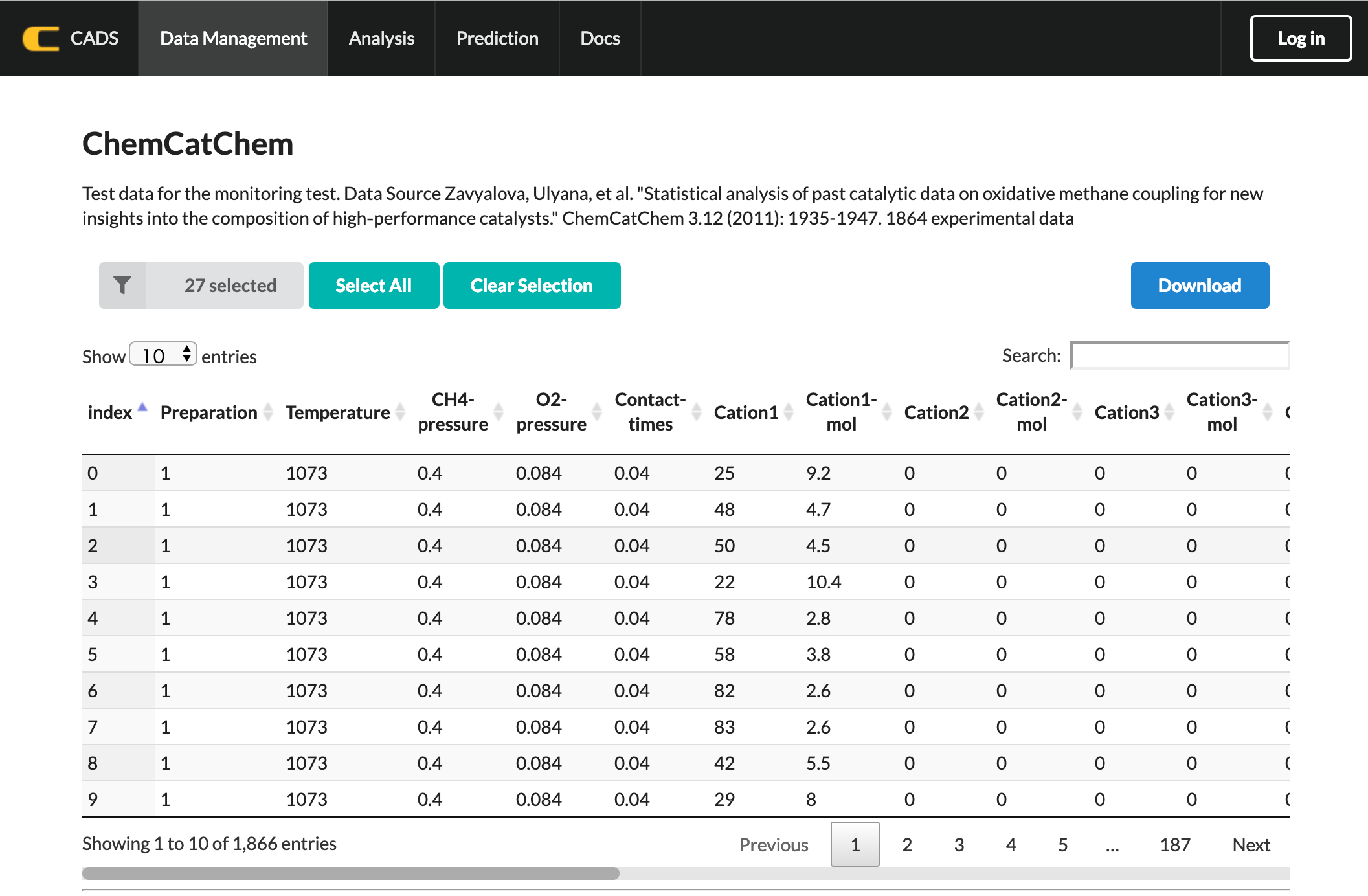
Brief Category Explanations
Cation 1–4 – cation composition of catalysts
Cation 1–4 Mol – in molar fractions
Anion 1–2 – anion composition of catalysts excluding oxygen in molar fractions
Anion 1–2 Mol – in molar fractions
Support 1, 2 – cation composition of supports
Support 1, 2 Mol – in molar fractions
>> Atomic number is assigned for Cation, Anion, and Support.
Preparation – Sample Preparation method
>> Numbers are assigned according to the methods listed below:
0 (no data)
1 Impregnation
2 Mech. Mixing
3 n.a.
4 Precipitation
5 Pyrolysis
6 Sol-gel
7 Therm.decomp.
Temperature – operating temperature in K;
p(CH4) and p(O2)- partial pressures of methane and O2 in bar;
Contact time - relation between catalyst bed volume and volumetric flow in seconds;
CH4 Conversion % – methane conversion in mole percentages;
C2 Selectivity - selectivity to ethane and ethylene in mole percentages;
COx – selectivity to CO and CO2 in mole percentages;
C2 Yield – ethane and ethylene yield – methane conversion ・ selectivity to ethane and ethylene, in mole percentages.
C2 Yield – ethane and ethylene yield in 3 classes: 0:0%-10%,1:10%-20%,2:20%-30%,3:30%+
"ChemCatChem" Data Source:
Zavyalova, Ulyana, et al. "Statistical analysis of past catalytic data on oxidative methane coupling for new insights into the composition of high‐performance catalysts."
ChemCatChem 3.12 (2011): 1935-1947.
1864 experimental data entries
Data Analysis¶
Data analysis is available under the “Analysis” submenu in the top menu. After clicking the Analysis submenu, you will see a list of the previously-saved analysis results.
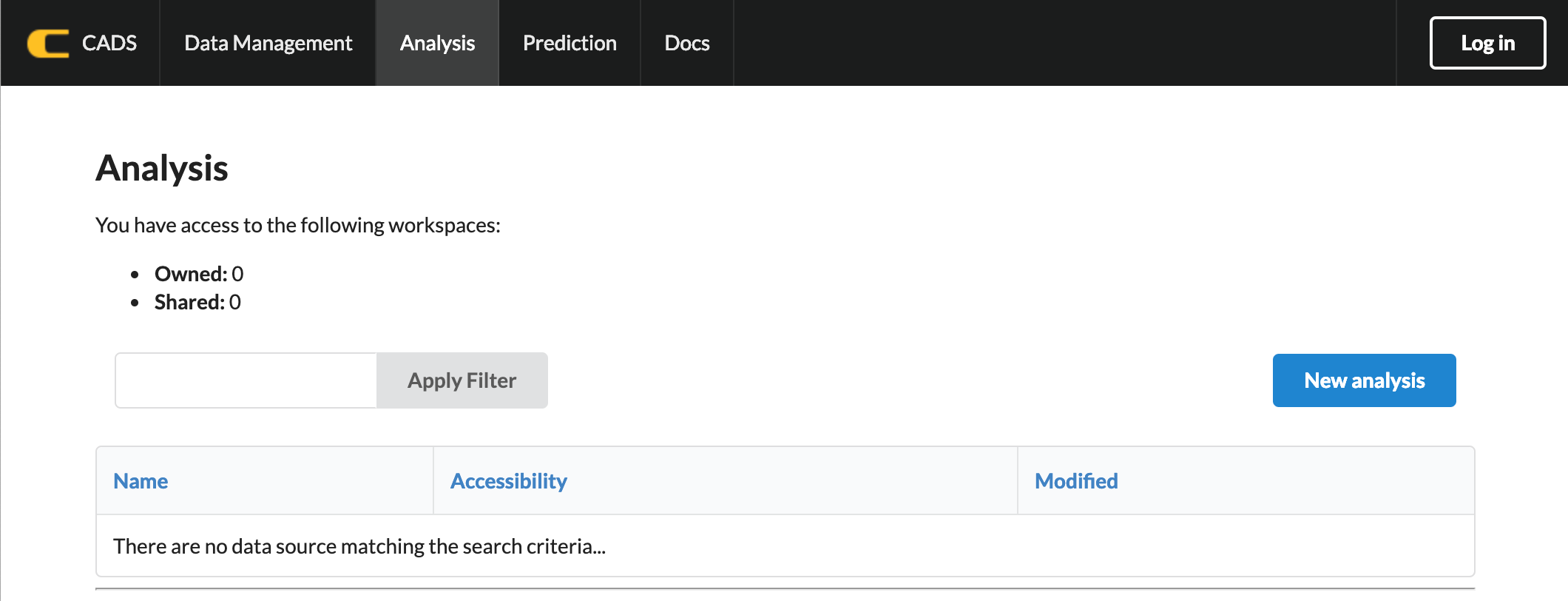
For new analysis, please click “New Analysis” at the beginning.
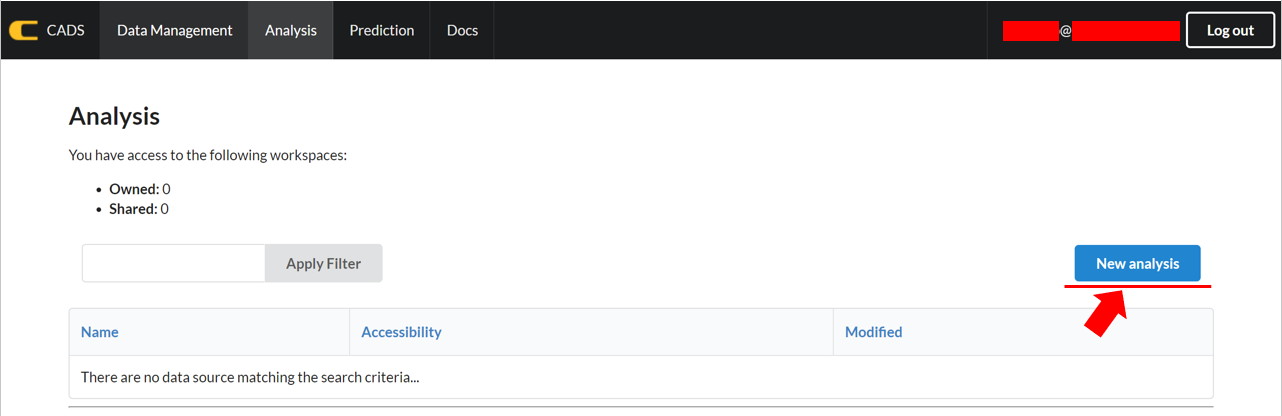
The data can be selected from the upper left of the tab for analysis.
A data analysis window can be added by clicking the “+ Add View” botton. The data analysis option will be selected on the menu that appears.
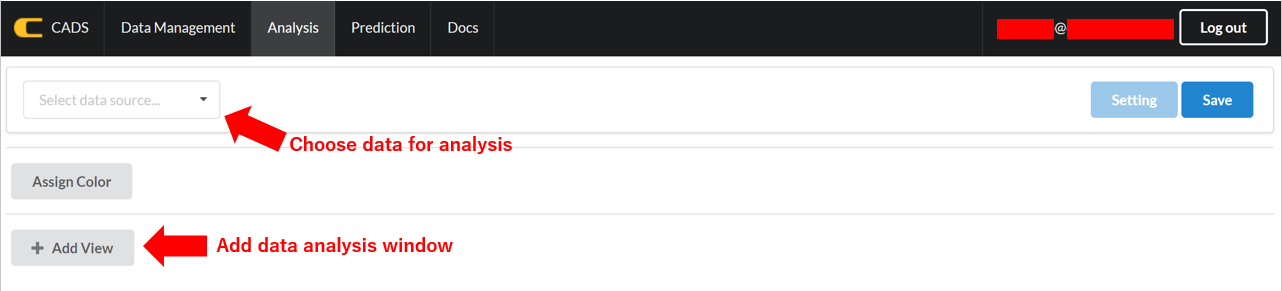
For example, “Scatter” represents a scatter plot, while “Table” lists the data and appropriate IDs for the loaded data.
Data analysis can be handled with using multiple windows simultaneously. Additionally, extra data dimensions can be viewed by implementing “Color Assignment”, where the color gradient of the scatter plot can reflect the data type of choice.
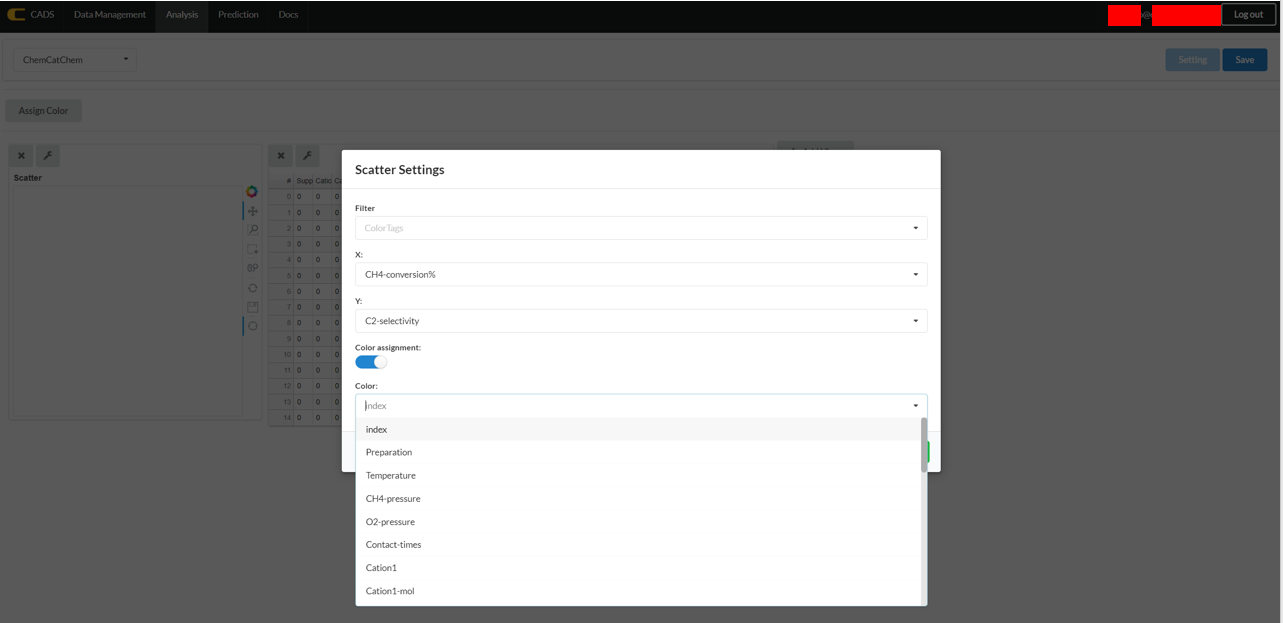
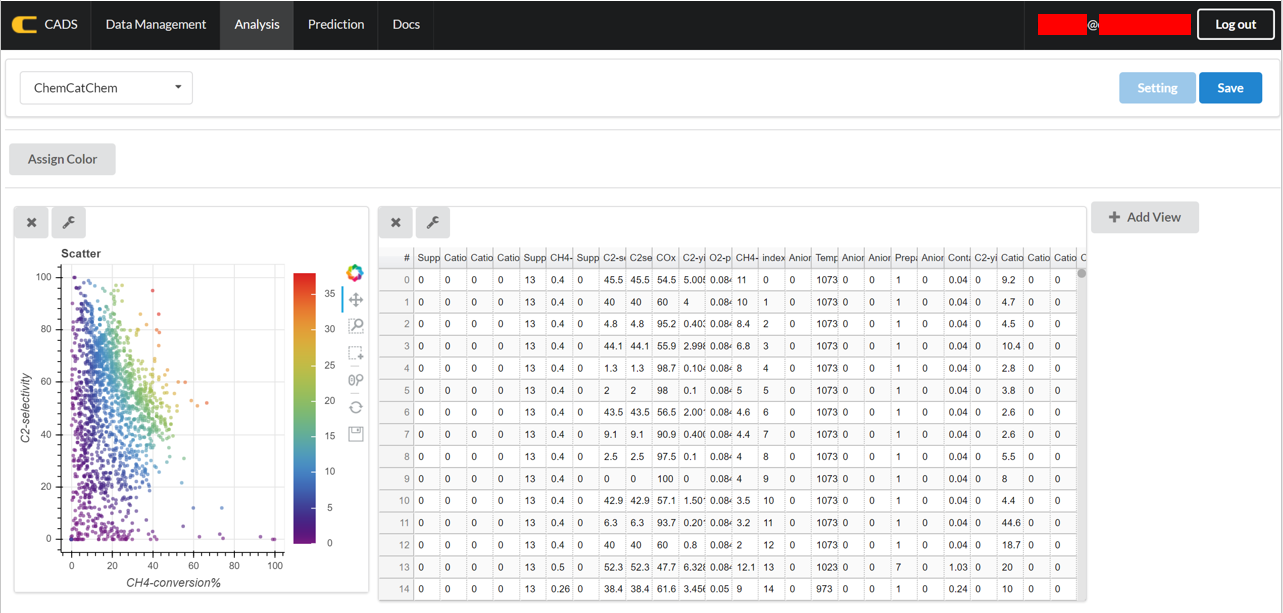
An analysis window can be deleted by selecting the “X” button in the upper left corner of the analysis window in question. The wrench icon in the upper left corner of the analysis window can be selected in order to select data columns for data analysis. For example, the wrench icon for a scatter plot window can be selected in order to select the data columns for the x and y axes.
Note that the data analysis window is linked to each other. For example, data that is selected on a scatter plot will be highlighted in its related data table.
Functions¶
Analysis can be carried out through the interaction of multiple windows, making it possible to work in parallel to other data analysis-related windows.
The following functions are currently available on CADS:
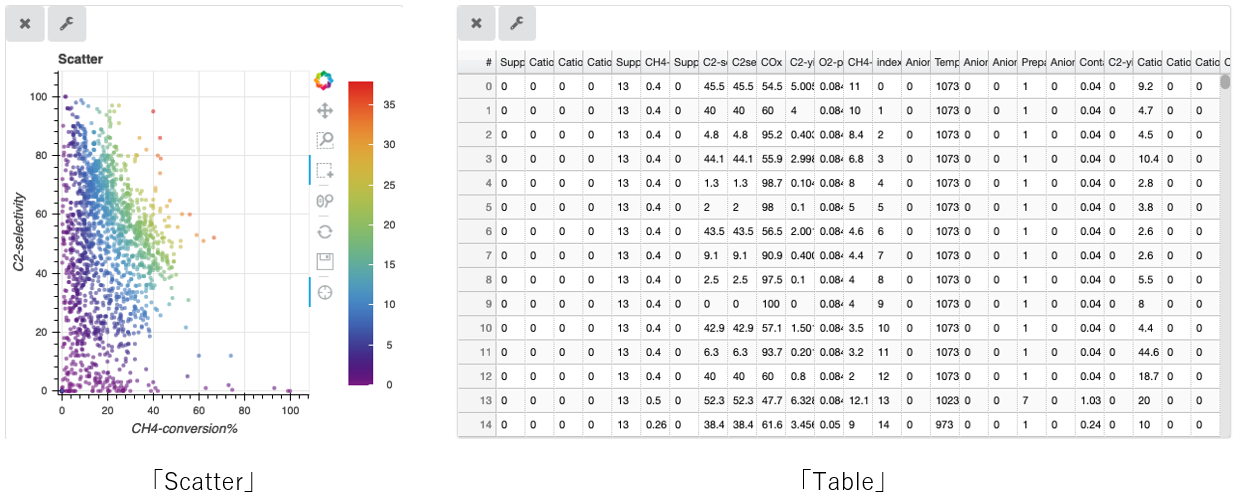
「Scatter」: Scatter plotting function in three dimensions: x axis, y axis, and color gradient of the plotted data.
「Table」: Data table of the loaded data: organization of data in descending or ascending order is available by clicking the data column labels.
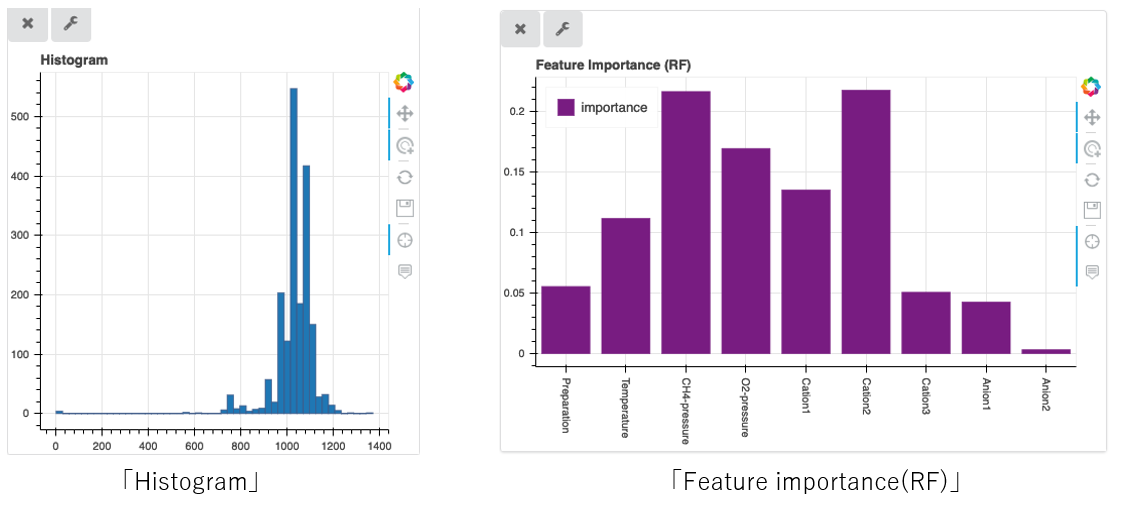
「Histogram」: Histogram visualization of data.
「Feature Importance (RF)」: Graph visualization of “Feature Importance” based on the “Random Forest Regression” algorithm.
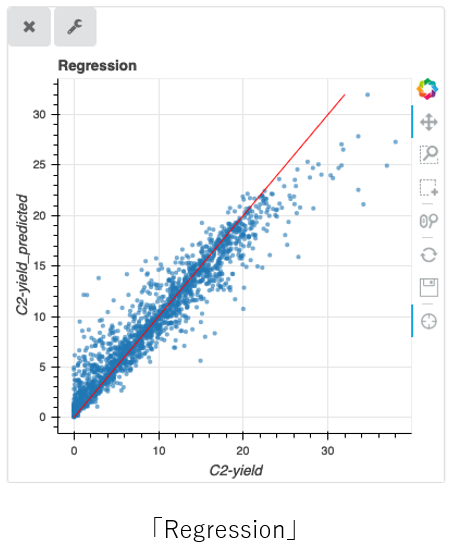
「Regression」: Tool for regression analysis, visualising a scatter plot of true data (x-axis) and predicted data by the trained “feature” data (y-axis). This function aims to evaluate the regression results. Good regression can be judged as “Feature” ≒ “Target”,where the scatter concentrates on the the red line on the scatter plot. The currently available algorithms are as follows: “Random Forest”, “Linear Regression”, “LASSO”, and “Support Vector Machine”.
Reference:
https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html
Analysis results are saved by clicking the “Save” botton on the upper right. The data is saved with the accessibility setting “Private” as the default setting.
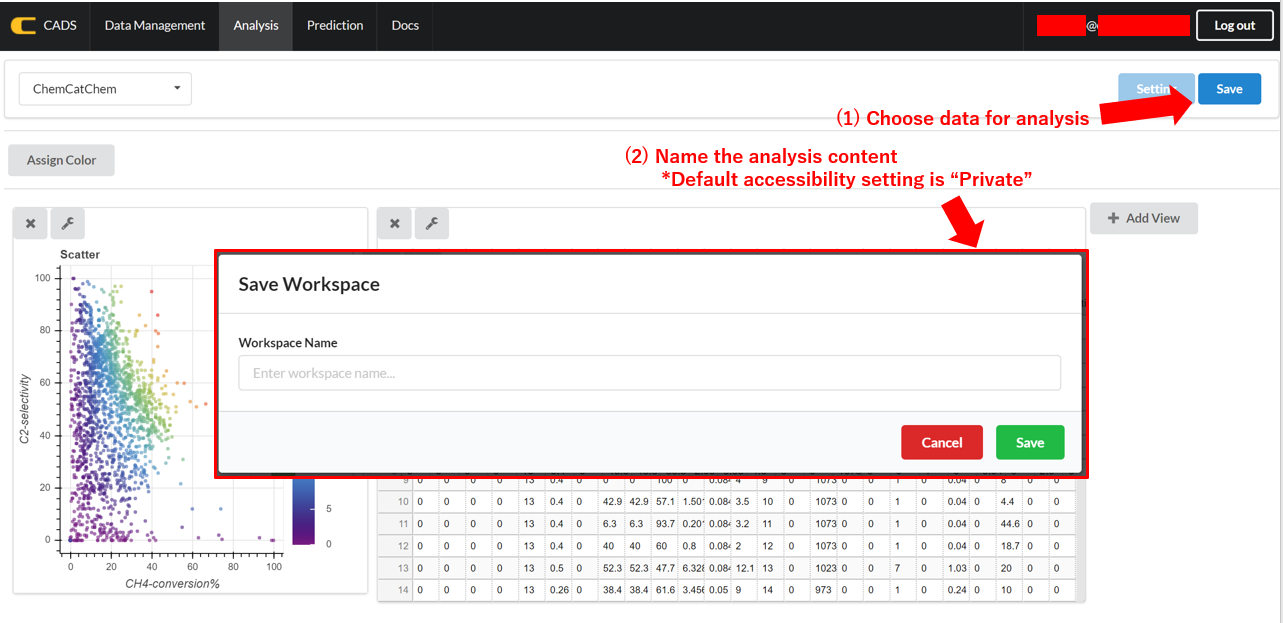
More detailed analysis data saving options are available by clicking the “Settings” button that appears on the upper right corner of the menu bar.
These saving options are set to the same as those in the “Data Management” menu, such as “Name of Analysis”, “Description” and “Accessibility”.
CAUTION:
"Accessibility" is the setting window for the accessibility of uploaded data.
PLEASE SET IT AS "Private" IF YOU ARE A BEGINNER OF THIS PLATFORM.
The setting "Public" allows other site users to access your uploaded data.
Prediction by Selected Regression Model¶
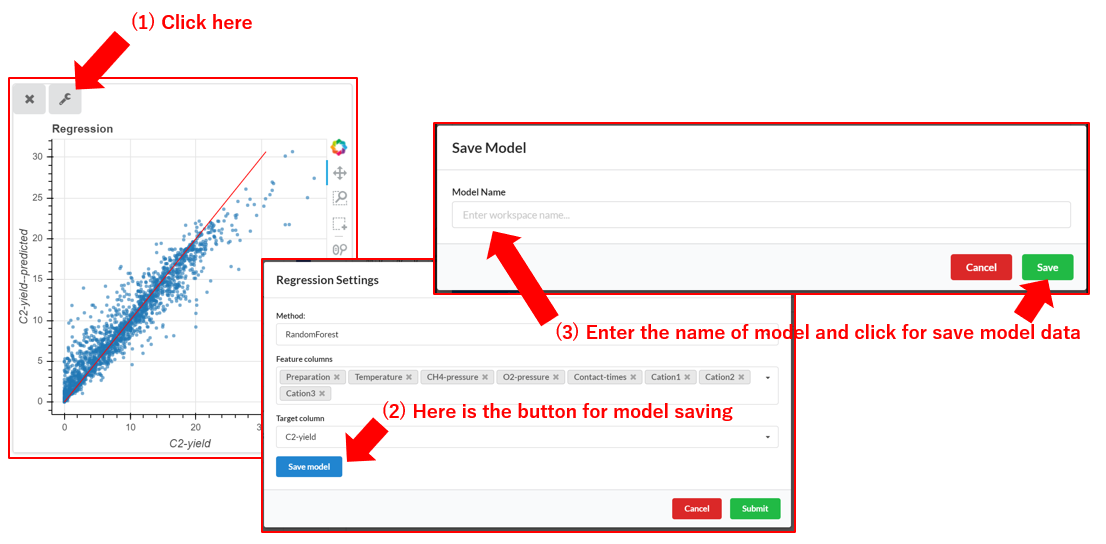
Prediction of objective variables is performed by the selected regression/classification model applied in the “Analysis” menu. For the use of this function, regression/classification model is evaluated and saved in the “Analysis” menu in advance.
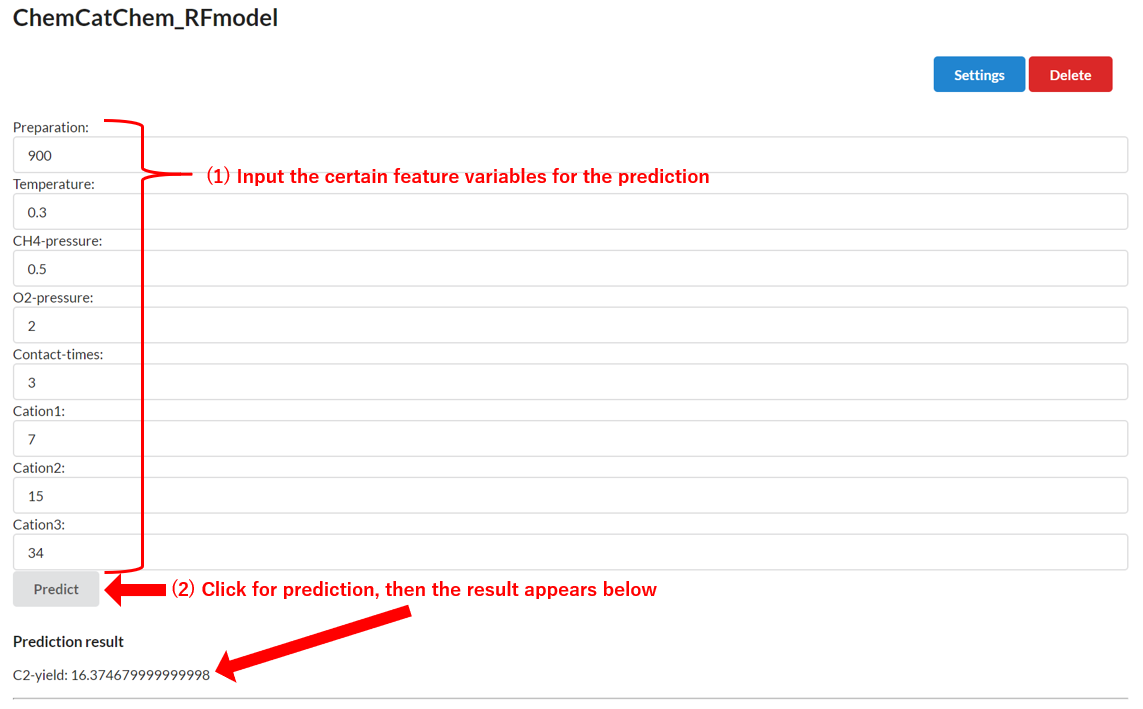
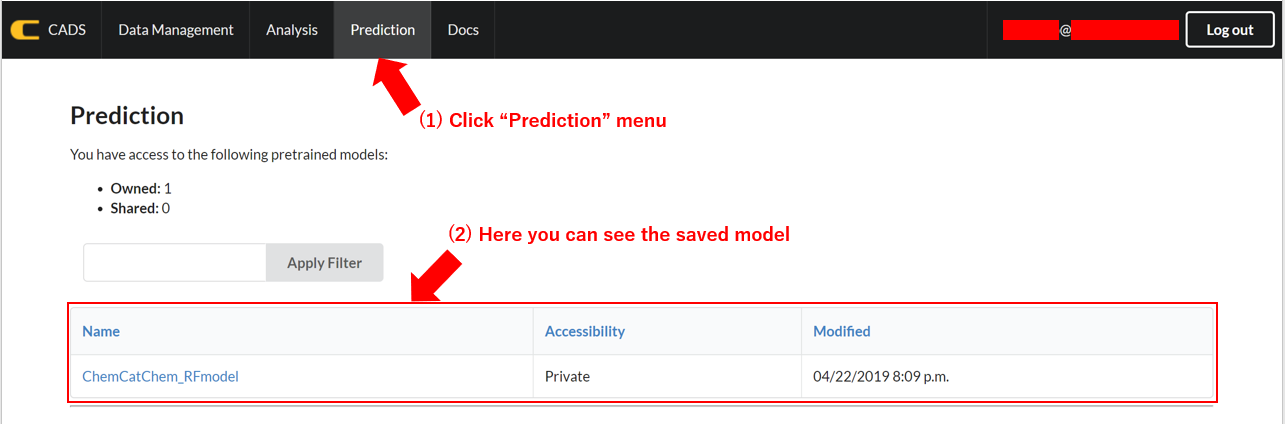
Prediction function is available under the “Prediction” submenu in the menu bar. After clicking, the saved regression/classification model(s) are listed in the window.
After clicking the regression/classification model, the “Prediction” window will appear. Prediction is performed by selecting certain values of a feature set on a saved model and clicking the “Predict” button. The prediction results can be saved in the same manner as the cases for “Data Management” and “Analysis”, with the options “Name of Prediction”, “Description”, and “Accessibility”.